3 New Agents
30 New Skills
30 Days
$30k
Our forward-deployed engineers work with your team to build 3 Agents specific for your production environment.
The Agents are built on the RunWhen platform, but the Skills can be used stand-alone CLI tools or with Claude, MS365, Gemini...
No long term commercial or technical commitments.
Example Agents...
The Agents shown below were all recently buit on our platform, proven in Fortune 100 mission critical environments with hundreds of thousands of Agent runtime hours.
Alert Triage Agents

Optimized to handle noisy alerts without spending too many tokens.
Basic triage to figure out the apps, infrastructure or data need immediate attention from experts... or their Agents.
Deep Investigation Agents
.svg)
Agents that work with experts.
Read logs, metrics configuration changes, code changes, dependencies, history, SRE notes... Write tickets that make engineers say "thank you."
Infra Remediation Agents

Scale up, scale down, roll back, restart...SAFELY.
Approval flows, GitOps, RBAC, Human-In-The-Loop, Fully Automated. Every service in every team in every organization has unique needs.
FinOps Action Agents

Cost analysis without action saves no budget.
A complete FinOps Agent needs to be work closely with top engineers to scale down, closely monitor health and emergency scale back up.
Developer <> Prod Agents

Help developers see their work running in prod.
Daily newsletters, question-answering, understandable observability and a deep sense of shared ownership.
Developer Self Service Agents

Reduce platform team escalations by 60%.
Is the test env down? Is there a script for that? How do I get into the DB? Was it really my code?
Infra Readiness Agents
.png)
Catch infrastructure trends before they become incidents.
Are we filling up storage? Gradually running out of memory? Queues piling up? Keep an eye on all of it without alert noise or confusion in a daily report.
Release Readiness Agents

Catch application incidents before they happen.
Is this release consuming more resources or throwing more errors than the last release? What changed -> was it expected -> write a readiness report.
Getting more headcount? Nope. Building more dashboards? Groan.
Write more runbooks? Yuck. Build agents instead.
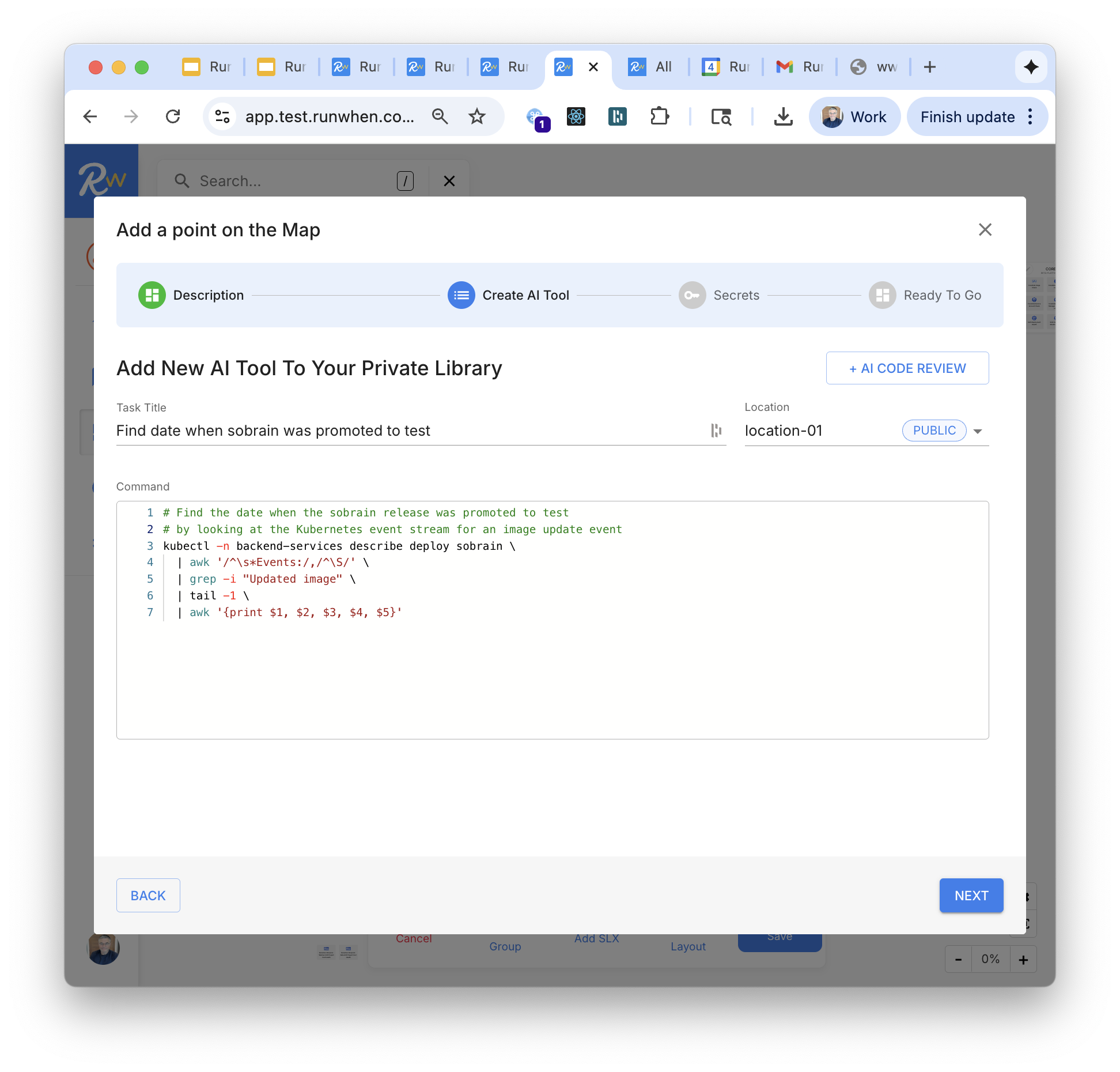
Safe-For-Production Skills included on day 1
With a Kubernetes or cloud credential, our set-up tools build thousands of safe-for-production Skills tailored for your applications, open source, infrastructure and toolchain... ready on day 1.
Add a Skill to an Agent. Grant acess to your team. You are up and running.

See what can be
done in 30 days?
If you decide the RunWhen platform is not for you, your team can use the Skills as stand-alone CLI tools or use them with Claude, MS360, LangGraph...
No long term commercial or technical commitments.

Developer Self-Service
Unblock developers waiting for help triaging CI/CD issues, finding platform automation, getting information to re-create issues in production
.svg)
Faster MTTR,
fewer escalations
Empower on-call first responders to do more without escalating -- alert triage, root cause analysis, deep investigations, standard operating procedures, remediation.
High accuracy SRE Agents
Most AI SRE tools turn 100 alerts into 20 hypotheses. This doesn't help anyone.
Helpful agents bridge observability with automation. Stacktraces in logs? Spike in metrics? Double check prod with automated diagnostics before making a fuss.
Wrap this in a Skill. Add the Skill to an Agent. Anyone on the team can use it.

Build your own safe-for-production Skills
Our Skill Building harness ensures that new skills built by your team follow our safe-for-production design pattern. They can be used with all major Agent platforms, and are optimized for lower token usage and extra safety with RunWhen Agents.
RunWhen Agents can run Skills in response to events, in cron jobs or with a human in the loop. Armed with real-time context about dependencies and health in the environment, they give excellent recommendations on which Skills to run next.
Skills built with the RunWhen Skill Building Harness go through multiple levels of AI code review before an Agent can pick them up. It is an AI-forward CI/CD pipeline built specifically for code that will access production.
.png)

Keep observability budgets in check with diagnostic Skills
With AI coding, automating diagnostics is faster than building dashboards. No more quirky cardinality problems or logging "just in case" that racks up expensive observability bills.
Wrap these diagnostics in a Skill. Add this Skill to an Agent.
Anyone can simply ask the Agent and see what it found in simple language. No more "what does this metric mean"?

Getting started with RunWhen

FOREGROUND AGENTS
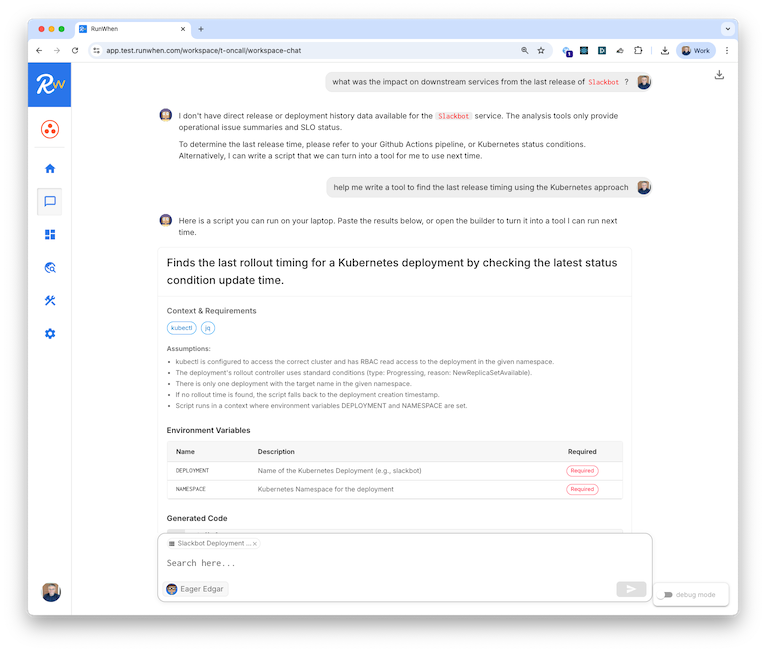
Ask questions for root cause analysis, configuration, cost, remediation and other topics.
The platform will suggest Skill-based automation to run or pull insights from the database of prior runs.

BACKGROUND AGENTS
Agents are constantly running agentic automation in the background, identifying issues that need attention.
Ask about what happened yesterday, or connect issues to notifications, remediations, etc.

30 DAYS?
Our FDEs or our partners will work with your team to build 30 new safe-for-production Skills for your infra, apps, data and workflows.
This is enough to get most teams into daily production use.

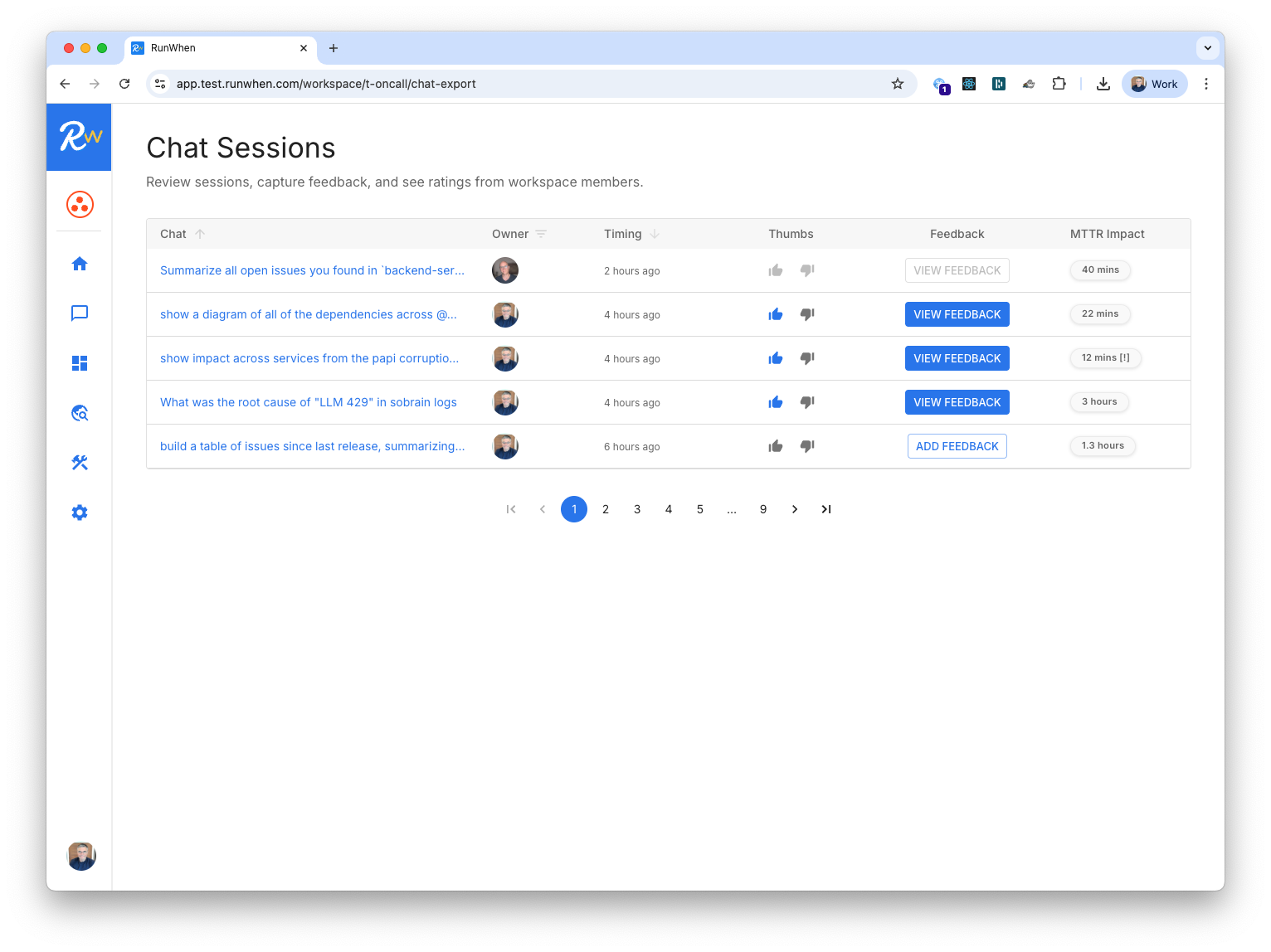
THUMBS UP?
Get AI-enhanced feedback from your users, showing where new tools should be prioritized for investigation, remediation, reporting or other uses.
Product management built in by design.


Can my team deploy RunWhen?
We work in the strictest financial services, health care and government environments in the industry

A (paid) community?
We are helping experienced engineers become AI SRE consultants and paid community contributors.




.svg)



